
Blog Post 4 - Fake News Classifier with Tensorflow
With the rapid development of technology, we are exposed to large amount of all kinds of information all the time. Our generation knows that how difficult it is to extract effective information because of all the “fake” news. Wouldn’t it be nice if we can create an algorithm that helps us detect fake news?
In this Blog Post, we will learn to develop and assess a fake news classifier using Tensorflow.
TensorFlow
TensorFlow is designed to help you build models easily. It has a set of APIs that makes it simple to learn and implement machine learning. We can also easily train our models with TensorFlow.
Data Source
Our data for this blog originally comes from the article:
- Ahmed H, Traore I, Saad S. (2017) “Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. In: Traore I., Woungang I., Awad A. (eds) Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments. ISDDC 2017. Lecture Notes in Computer Science, vol 10618. Springer, Cham (pp. 127-138).
This data can be accessed from Kaggle. However, the data we are using today has already been cleaned and split into training and testing sets.
Important Packages
Before we start, here are the packages we will need for today’s blog.
import tensorflow as tf
import numpy as np
import re
import string
import pandas as pd
from matplotlib import pyplot as plt
# important tensorflow packages
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow import keras
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from tensorflow.keras.layers.experimental.preprocessing import StringLookup
# for embedding visualization
import plotly.express as px
import plotly.io as pio
pio.templates.default = "plotly_white"
§1. Acquire Training Data
train_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_train.csv?raw=true"
df = pd.read_csv(train_url)
df.head()
| Unnamed: 0 | title | text | fake | |
|---|---|---|---|---|
| 0 | 17366 | Merkel: Strong result for Austria's FPO 'big c... | German Chancellor Angela Merkel said on Monday... | 0 |
| 1 | 5634 | Trump says Pence will lead voter fraud panel | WEST PALM BEACH, Fla.President Donald Trump sa... | 0 |
| 2 | 17487 | JUST IN: SUSPECTED LEAKER and “Close Confidant... | On December 5, 2017, Circa s Sara Carter warne... | 1 |
| 3 | 12217 | Thyssenkrupp has offered help to Argentina ove... | Germany s Thyssenkrupp, has offered assistance... | 0 |
| 4 | 5535 | Trump say appeals court decision on travel ban... | President Donald Trump on Thursday called the ... | 0 |
As we can see, there are three important columns in this dataset, title, text, and fake. In the fake column, the data is already encoded to 0 (not fake news) and 1 (fake news), so we don’t need to encode this column anymore.
§2. Make TensorFlow Datasets
TensorFlow Dataset has a special Dataset class that’s easy to organize when writing data pipelines.
In this section, we want to write a function called make_dataset to construct our Datasetthat has all the stopwrods removed from text and title and takes two inputs text and title of the form ("title", "text")
# define stopwords
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stop = stopwords.words('english')
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
def make_dataset(df):
'''
this function removes stopwords from desired columns and constructs tensorflow dataset with two input and one output
input:
df - the dataframe of interest
output: a tf.data.Dataset
'''
# remove stopwords from text and title
df = df[['text','title', "fake"]].apply(lambda x: [item for item in x if item not in stop])
# construct tf dataset
# construct dataset from a tuple of dictionaries
# the first dictionary is the inputs
# the second dictionary specifies the output
data = tf.data.Dataset.from_tensor_slices(
({
"title" : df[["title"]],
"text" : df[["text"]]
},
{
"fake" : df[["fake"]]
}))
# batch the dataset to increase the speed of training
data = data.batch(100)
return data
Now, we use the function we just wrote to construct our Dataset.
data = make_dataset(df)
Next, we’ll split the dataset into training and validation sets. We want 20% of the dataset to use for validation.
# shuffle data
data = data.shuffle(buffer_size = len(data))
# 80% of the dataset is for training
train_size = int(0.8*len(data))
# so we have validation size of 0.2 approximately
train = data.take(train_size)
val = data.skip(train_size)
# check the size of training, validation, testing set
len(train), len(val)
(180, 45)
We have 180 batches in training set and 45 batches in validation set, which is exactly 0.8 : 0.2. We have successfully split the data into training and validation sets.
§3. Create Models
As there are two potential predictors, there are three different potential models: model that focus on only the title of the article, the full text of the article, and both.
Which one is the most effective?
To address this question, let’s create 3 corresponding TensorFlow models.
- In the first model, we use only the article title as an input.
- In the second model, we use only the article text as an input.
- In the third model, we use both the article title and the article text as input.
Compared with Keras sequential API, Keras functioanl API can handle shared layers and multiple inputs, which is exactly what we need for our inquery. For the first two models, we also don’t have to create new Datasets. Instead, just specify the inputs to the keras.Model appropriately, and TensorFlow will automatically ignore the unused inputs in the Dataset.
standardization
First, we want to standardize text by removing capitals and punctuation.
def standardization(input_data):
'''
this function takes a tensorflow dataset as input
and convert all text to lowercase and remove punctuation.
'''
lowercase = tf.strings.lower(input_data)
no_punctuation = tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation),'')
return no_punctuation
vectorization
Next, we want to represent text as a vector. To be specific, we replace each word in the text with its frequency rank.
# we only want to track the top 2000 distinct words
size_vocabulary = 2000
# vectorization layer learns what words are common
vectorize_layer = TextVectorization(
# standardize each sample
standardize=standardization,
max_tokens=size_vocabulary, # only consider this many words
output_mode='int',
output_sequence_length=500)
# adapt the vectorization layer to title and text in the training data
vectorize_layer.adapt(train.map(lambda x, y: x['title']))
vectorize_layer.adapt(train.map(lambda x, y: x['text']))
Now that we’ve prepared our data, it’s time to construct our models. The first step is to specify the two inputs using keras.Input for our model.
Note that both title and text contain just one entry for each news, so the shapes are (1,).
# inputs
title_input = keras.Input(
shape = (1,),
# name for us to remember for later
name = "title",
# type of data contained
dtype = "string"
)
text_input = keras.Input(
shape = (1,),
name = "text",
dtype = "string"
)
Hiden Layers
Let’s now write a pipeline for the titles and text. Since title and text are two different pieces of text but share similar vocabulary, we can use shared layers to encode inputs.
# shared embedding layer
shared_embedding = layers.Embedding(size_vocabulary, 20, name = "embedding")
# pipeline for title
title_features = vectorize_layer(title_input)
title_features = shared_embedding(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.GlobalAveragePooling1D()(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.Dense(32, activation='relu')(title_features)
#pipeline for text
text_features = vectorize_layer(text_input)
text_features = shared_embedding(text_features)
# the dropout rate is higher because lower rate led to overfitting by experiments
text_features = layers.Dropout(0.7)(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.5)(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
Although it looks like we are performing vectorization on inputs now, the vectorization actually won’t take place until we actually run the model.
Now we can specify the respective output layers for three models. For the last model, we will need to concatenate the the ouput of title pipeline with the output of the text pipeline.
# the name of the output layer matches the key corresponding to the target data
# output layer for model1 that only focus on title
title_output = layers.Dense(2,name='fake')(title_features)
# output layer for model2 that only focus on text
text_output = layers.Dense(2,name='fake')(text_features)
main = layers.concatenate([title_features, text_features], axis = 1)
main = layers.Dense(32, activation= "relu")(main)
# output layer for model3 that focus on both
output = layers.Dense(2, name = "fake")(main)
It’s time to create our models! We can do so by specifying the input(s) and output. The plot_model function provides an easy way to visually examine the structure of our model, so it’s nice to take a look. After compile our model, we can start training it.
def train_model(input, output):
'''
this function fits and trains model and plot the training and validation accuracy
input:
input: the inputs for the model
output: the outputs for the model
return:
model: the model at interest
history: the history of validation loss
'''
# speficy the input and output
model = keras.Model(
inputs = input,
outputs = output
)
# compile the model
model.compile(optimizer = "adam",
loss = losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
# fit model
history = model.fit(train,
validation_data=val,
epochs = 50,
verbose = 0)
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
return model, history
Model 1 — with only title
Keras will automatically ignore the key 'text' since it doesn’t match our input.
model1, model1_history = train_model(title_input, title_output)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/functional.py:595: UserWarning:
Input dict contained keys ['text'] which did not match any model input. They will be ignored by the model.
# check the structure of model 1
keras.utils.plot_model(model1)
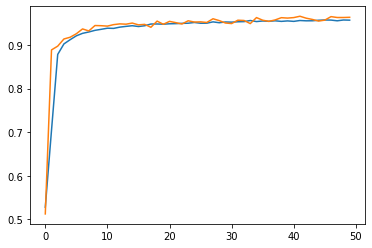
round(max(model1_history.history["val_accuracy"]), 4)
0.9662
Based on the training log and the plot, we can see that model 1 can reach validation accuracy of around 96%, which is pretty good!
Model 2 — with only text
Keras will automatically ignore the key 'title' since it doesn’t match our input.
model2, model2_history = train_model(text_input, text_output)
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/functional.py:595: UserWarning:
Input dict contained keys ['title'] which did not match any model input. They will be ignored by the model.
# take a look at the structure of model 2
keras.utils.plot_model(model2)
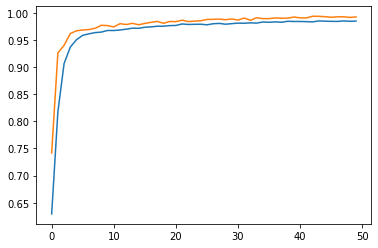
from statistics import *
round(median(model2_history.history["val_accuracy"]), 4)
0.9861
round(max(model2_history.history["val_accuracy"]), 4)
0.9935
By reading the training log and the plot, the validation accuracy is able to reach above 98% consistently. This is quite impressive!
Model 3 — with both title and text
model3, model3_history = train_model([title_input, text_input], output)
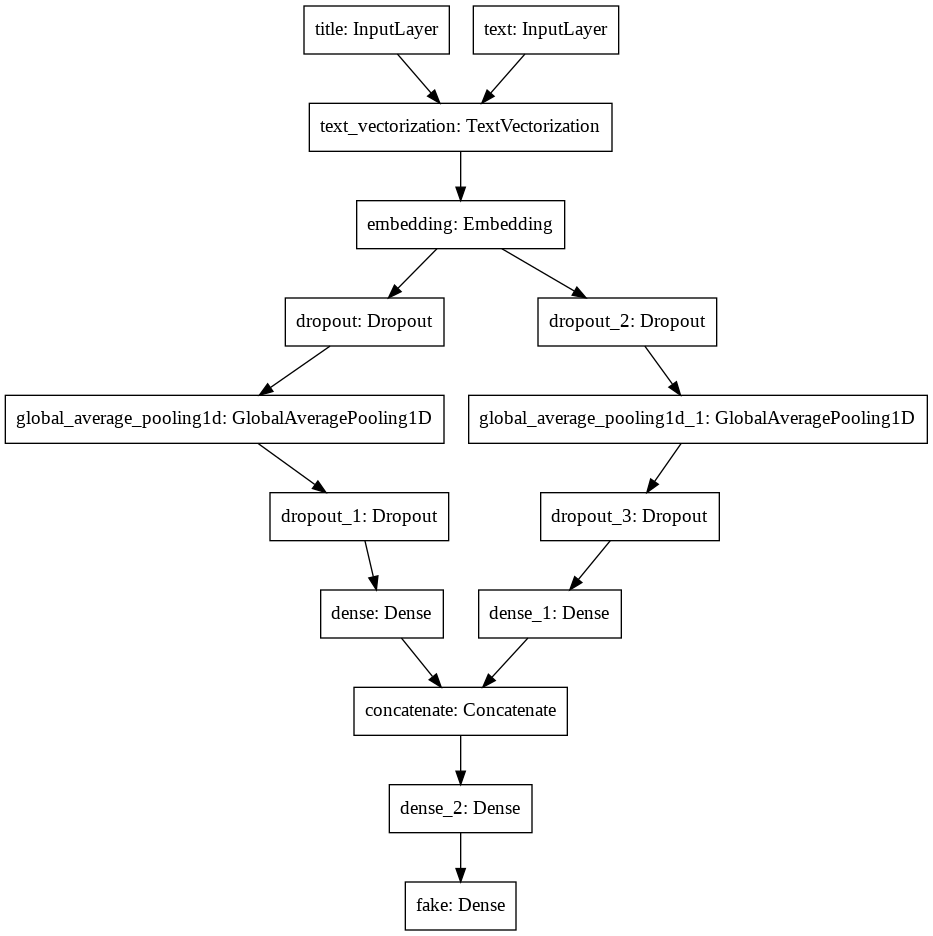
# take a look at the structure of model 3
keras.utils.plot_model(model3)
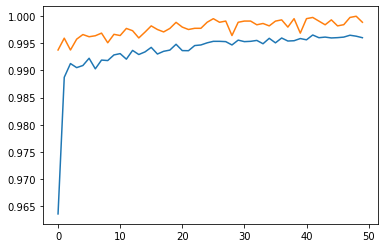
round(median(model3_history.history["val_accuracy"]), 4)
0.9981
round(max(model3_history.history["val_accuracy"]), 4)
1.0
Model 3 is able to consistently reach a validation performance of 99% by the training log and plot. Hence, we pick Model 3 to be our final model, i.e. the model that focuses on both the text and title.
§4. Model Evaluation
From last section, our best model focuses only on the text. Now let’s test this model’s performance on unseen test data.
test_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_test.csv?raw=true"
test = pd.read_csv(test_url)
test = make_dataset(test)
model3.evaluate(test)
225/225 [==============================] - 3s 15ms/step - loss: 0.0329 - accuracy: 0.9913
[0.03293461352586746, 0.991313636302948]
The accuracy is 99%! We have created a pretty good fake news detector.
§5. Visualizing Embeddings
We can take a step further to learn about which words are learned by our model to be good indicators of fake news by visualizing embeddings.
weights = model3.get_layer('embedding').get_weights()[0] # get the weights from the embedding layer
vocab = vectorize_layer.get_vocabulary() # get the vocabulary from our data prep for later
len(weights[0]) # the dimension of embedding is 20
20
from sklearn.decomposition import PCA
# reduce the dimension to 2
pca = PCA(n_components=2)
weights = pca.fit_transform(weights)
# a dataframe of our result
embedding_df = pd.DataFrame({
'word' : vocab,
'x0' : weights[:,0],
'x1' : weights[:,1]
})
Now we are ready to see the plot.
fig = px.scatter(embedding_df,
x = "x0",
y = "x1",
size = list(np.ones(len(embedding_df))),
size_max = 2,
hover_name = "word")
fig.show()
The graph is stretched horizontally and slightly vertically. By hovering the cursor on some of the points, we see reportedly, myanmar, rohingya, trumps, donald, barack are all stronger indicators for whether a news is fake or not.